Compilation Workflow
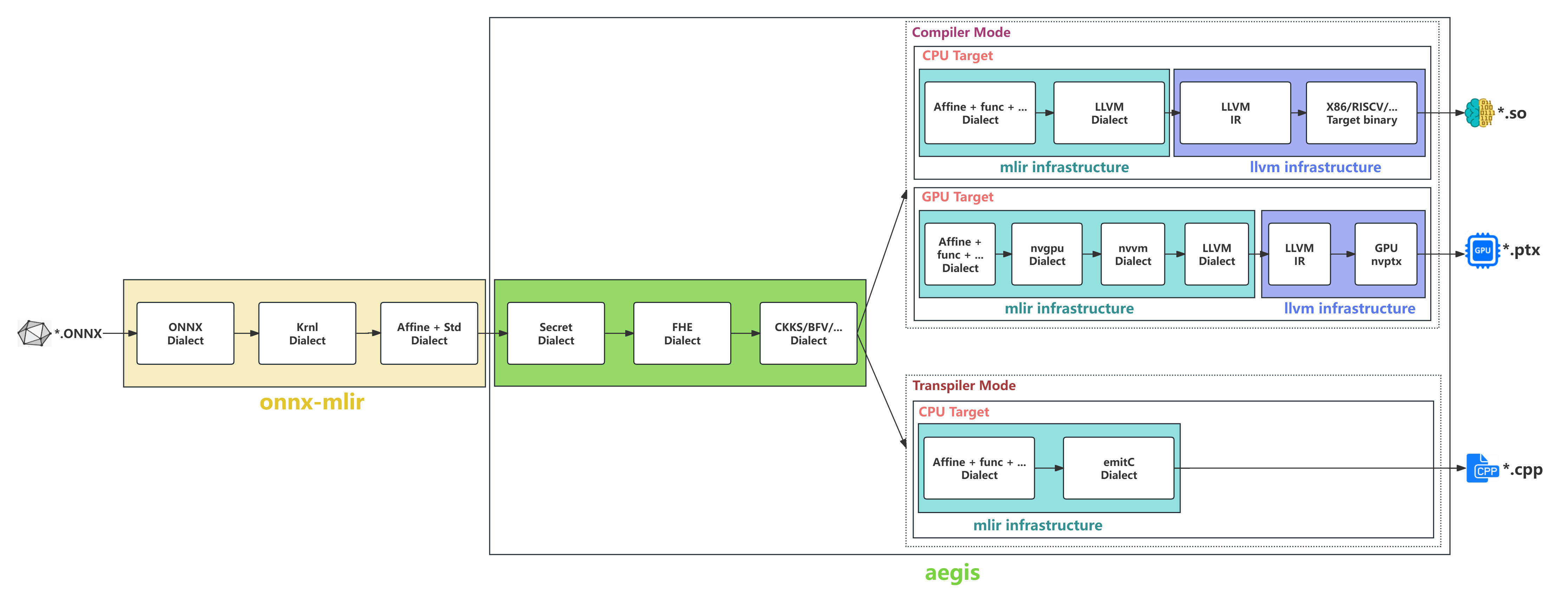
Aegis supports two compilation modes: transpiler mode and compiler mode. The compiler mode supports CPU and GPU targets.
-
Transpiler mode
- In transpiler mode, to generate source code for the CPU target, the built-in MLIR generated by the onnx-mlir (integrated in the Aegis frontend) is transformed using user-defined chain technique in the compilation domain, converting the built-in MLIR into a secret dialect, then secret dialects are progressively lowered to the MLIR emitC dialect, where fully homomorphic encryption operations are converted into function calls to the FHE cryptographic library wrappers (e.g., openFHE). Finally, the emitC dialect is converted into the actual *.cpp files through transformation pass.
-
Compiler mode
- CPU Target To generate CPU target object files, the built-in MLIR generated by onnx-mlir integrated into the Aegis frontend is transformed using user-defined chain technique in the compilation domain, converting the built-in MLIR into a secret dialect. Then, Aegis applies standard high-level optimization pass and lowers the secret dialect to a dialect specific to the selected FHE scheme (e.g., CKKS dialect, BFV dialect, BGV dialect, etc.). This FHE scheme dialect is then lowered to LLVM IR, which includes C API function calls to the FHE cryptographic libraries (e.g., openFHE). Finally, the LLVM IR is compiled and linked with the FHE library to produce the target executable file.
- GPU Target To generate GPU target object files, the built-in MLIR generated by onnx-mlir integrated into the Aegis frontend is transformed using user-defined chain technique in the compilation domain, converting the built-in MLIR into a secret dialect. Then, Aegis applies standard high-level optimization pass and lowers the secret dialect to a dialect specific to the selected FHE scheme (e.g., CKKS dialect, BFV dialect, BGV dialect, etc.). This FHE scheme dialect is then lowered to the GPU dialect and further lowered to LLVM IR, which includes CUDA API function calls for the FHE cryptographic libraries (e.g., cuFHE). Finally, the LLVM IR is compiled into an NVPTX assembly file compatible with the NVIDIA GPU platform and linked with the CUDA toolkit to generate the GPU target executable file.
Each transformation or lowering step involves multiple optimization pass.